地理空间数据库:空间索引的创建与查询
利用PostgreSQL/PostGIS扩展模块对空间数据索引管理,提升空间查询效率。
要求:
(1)理解空间索引的概念;
(2)掌握PostGIS:B-Tree、GiST、SP-GiST三类典型索引算法;
(3)能够对各类空间数据创建索引、优化索引。
1 概念回顾
1.1 PostGIS支持的索引
PostGIS默认支持三类空间索引:B-Tree、GiST、SP-GiST;
1、B-Tree索引
用于可以在一个方向上排序的数据,如数字(numbers),字母(letters),日期(dates)。地理数据不能再一个方向上排序,所以B-Tree不能用于地理数据。
R-Trees是将数据分解成矩形,子矩形,子子矩形等。R-Trees被一些数据库用于地理数据的索引。但是PostgreSQL的R-Tree实现没有GiST实现那么健壮。
2、GiST(Generalized Search Trees)索引
是“通用搜索树”,将数据分解成“东西在哪一边”,“东西覆盖什么”,“东西在什么里”,它可以用于广泛的数据结构,包括地理数据。重点处理:范围是否相交,是否包含,地理位置中的点面相交,或者按点搜索附近的点等。
GiST通过R-Tree去索引地理数据。
GiST用于加快各种不适用于B-Tree索引的不规则数据结构的查询速度。
注(1):一旦地理数据表超过几千行,你就需要建立一个索引来加快数据的空间搜索(除非你的所有搜索都基于非地理属性)。
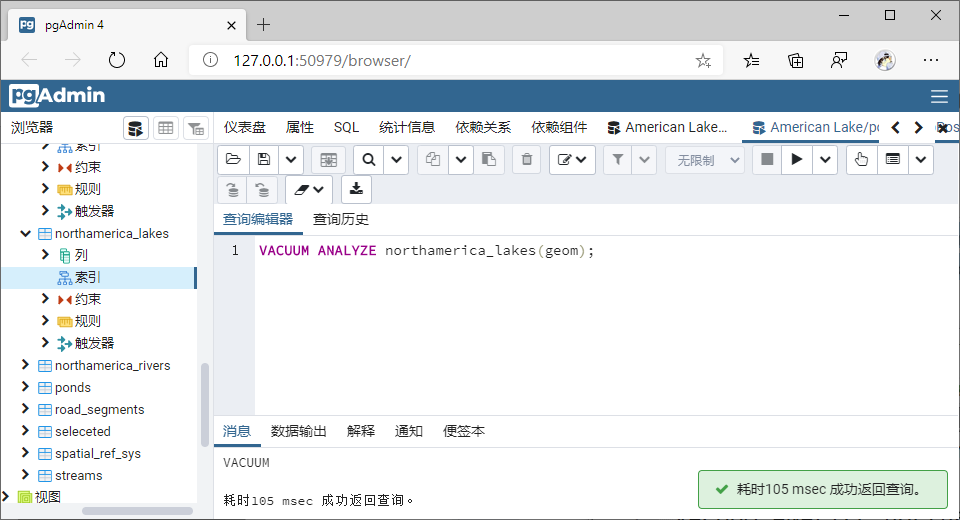
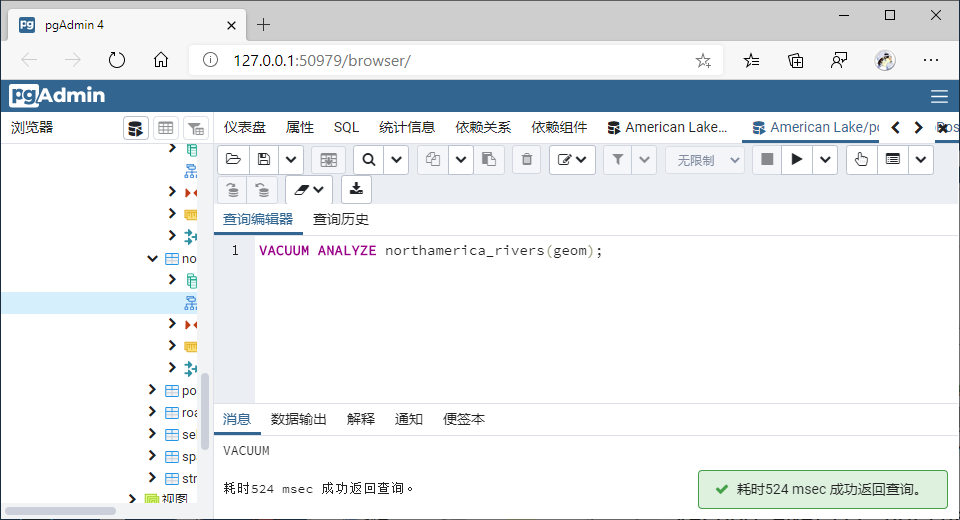
注(2):创建索引后,需要通知PostgreSQL收集表的统计数据,以便优化查询规则,否则默认不使用索引。
3、BRIN索引
是一种块范围索引,只存储包含在一组表块(称为范围)中所有行的所有几何图形的边界。因此,要求数据和物理位置关联,而且不能太频繁更新,在物理顺序和逻辑顺序越一致的列,越适合建立BRIN索引。PostgreSQL
9.5版本开始引入。大多数情况下,效率是低于GiST索引的。
【什么情况用BRIN,不用GiST?】
只要GiST索引的大小不超过数据库可用的RAM大小,并能负担存储和工作负责空间损失,就可以用GiST索引,否则考虑使用BRIN索引。
4、SP-GiST索引
SP-GiST是空间划分GiST(Space-partitioned
GiST)的简称。SP-GiST支持划分搜索树,它们可用于开发许多各种不同的非平衡数据结构,例如四叉树、k-d树和单词查找树。这些结构的共同特征是它们反复地将搜索空间划分成大小不需要相等的分区。匹配这些划分规则的搜索将会很快。
存储的也是几何对象的边界,可作为GiST的一种候选索引,其性能在几何对象存在众多相互重叠时,会优于GiST索引。
2 实验任务
以实验2北美+南美数据为基础,将作业二中题目一空间查询利用空间索引实现,并展示相关结果。具体要求:
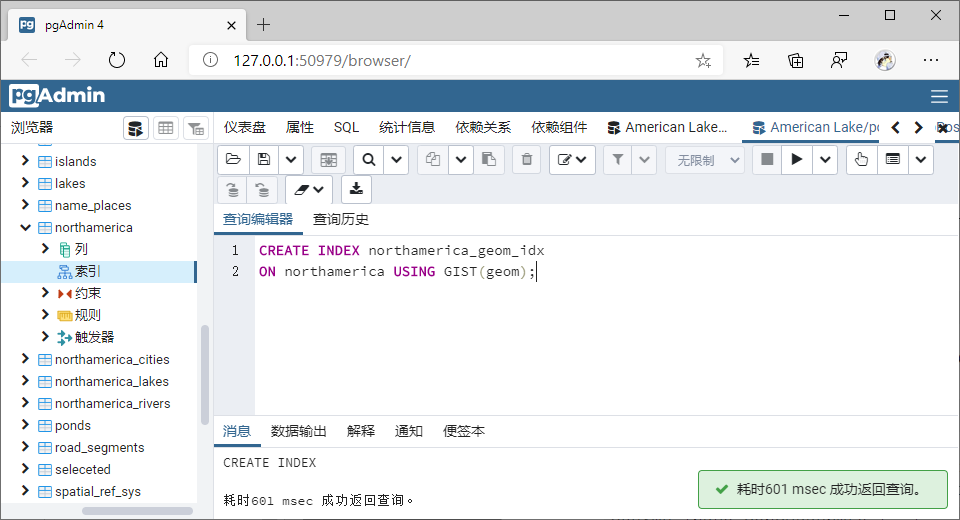
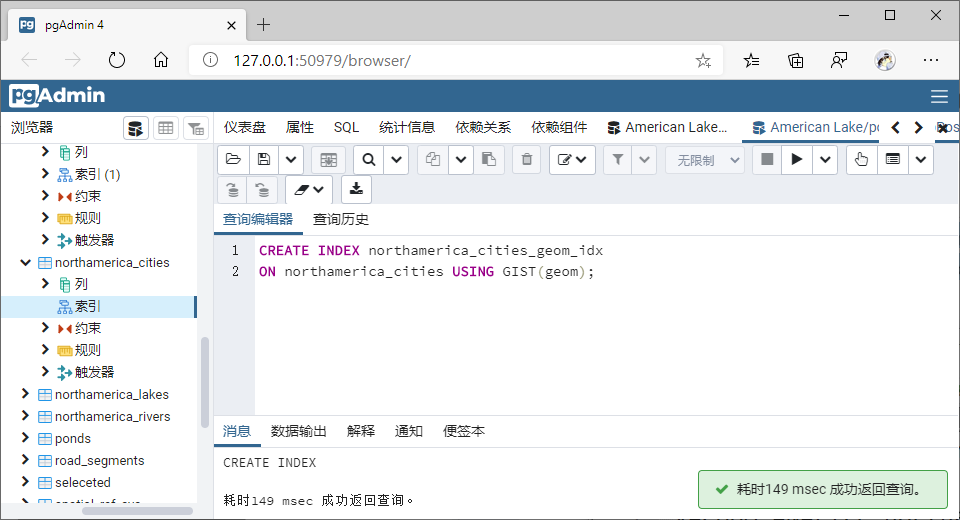
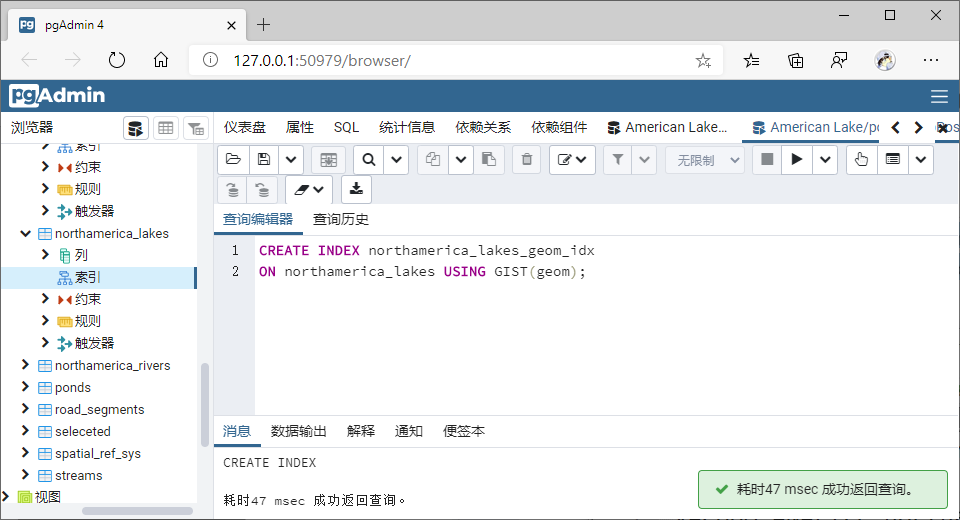
1、对北美数据相关几何字段建立GiST索引【postgresSQL会默认在geom字段建立索引】;
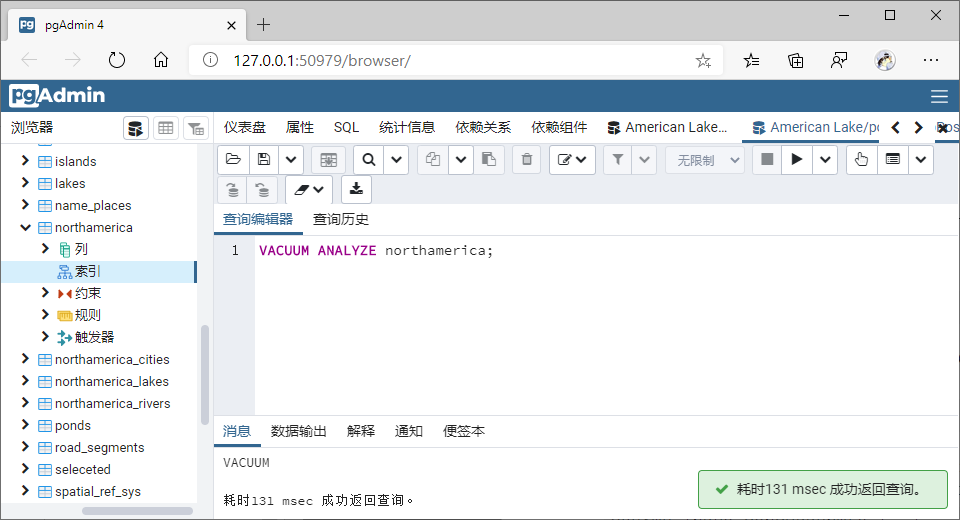
默认索引如下:
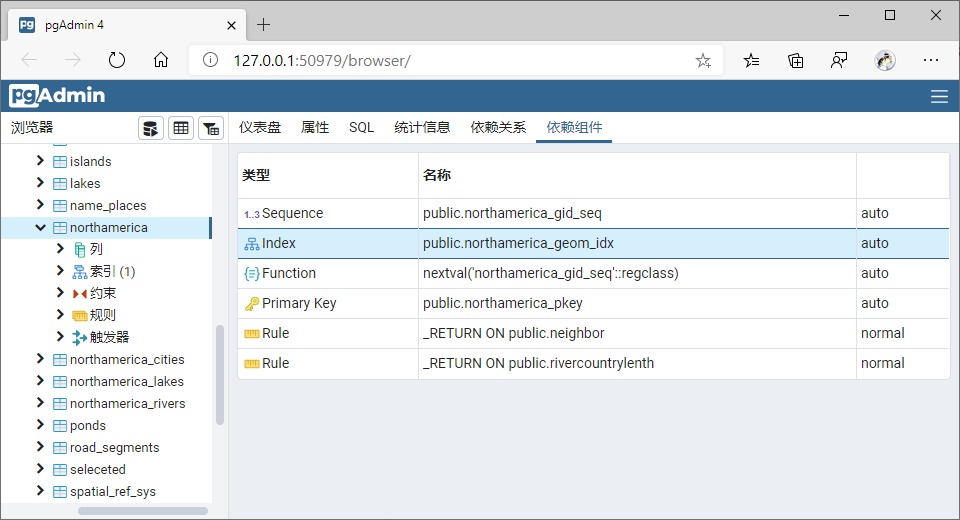
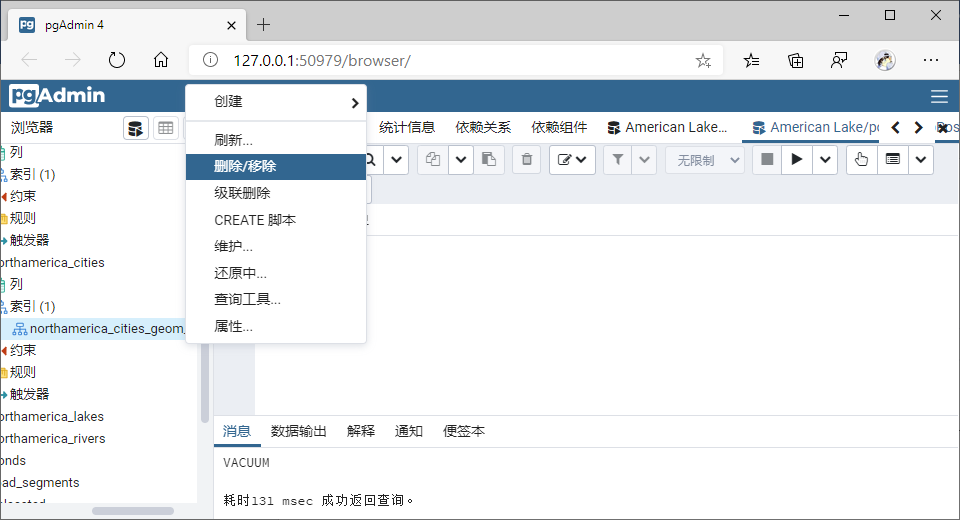
可以删除后重建;
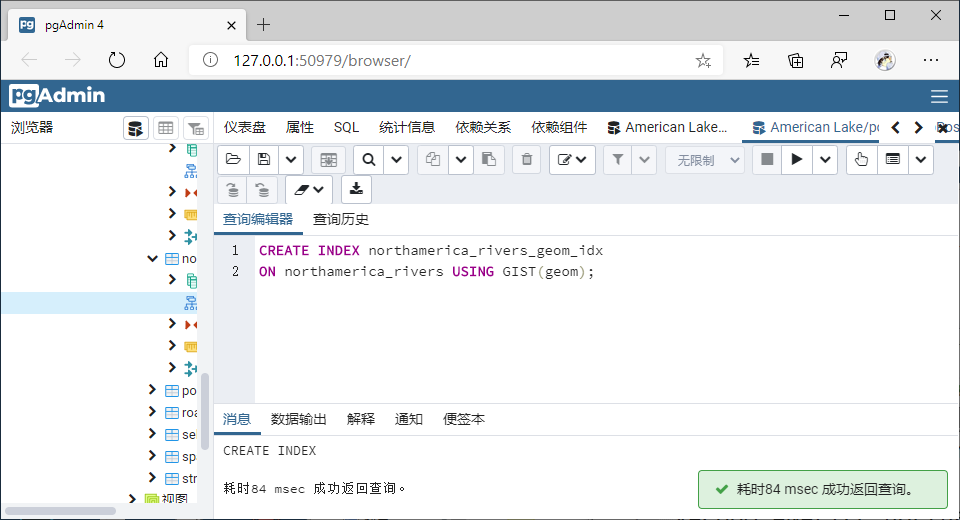
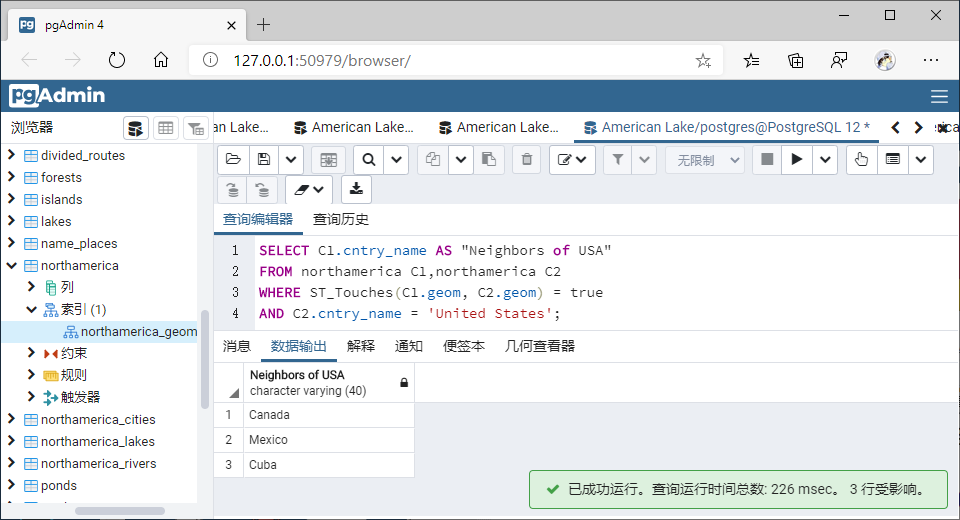
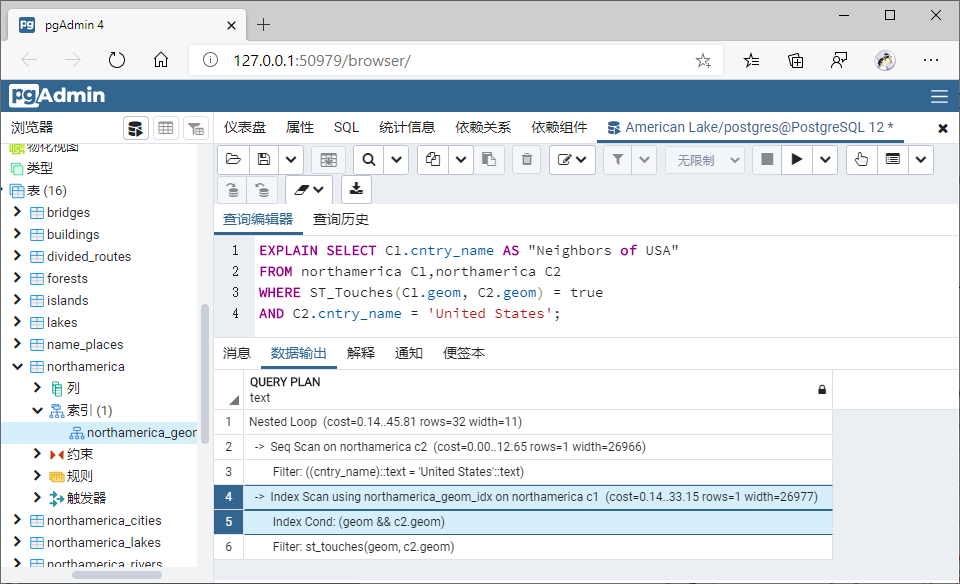
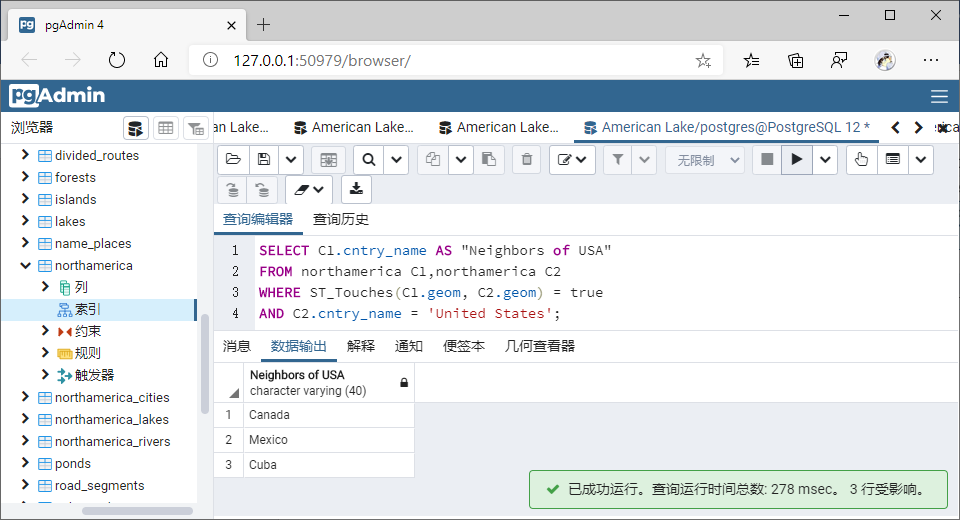
2、以其中一个空间查询(任选一个使用空间索引查询的函数即可)为例,展示建立GiST索引和不建GiST索引空间查询耗时差异;
①建立GiST索引时:
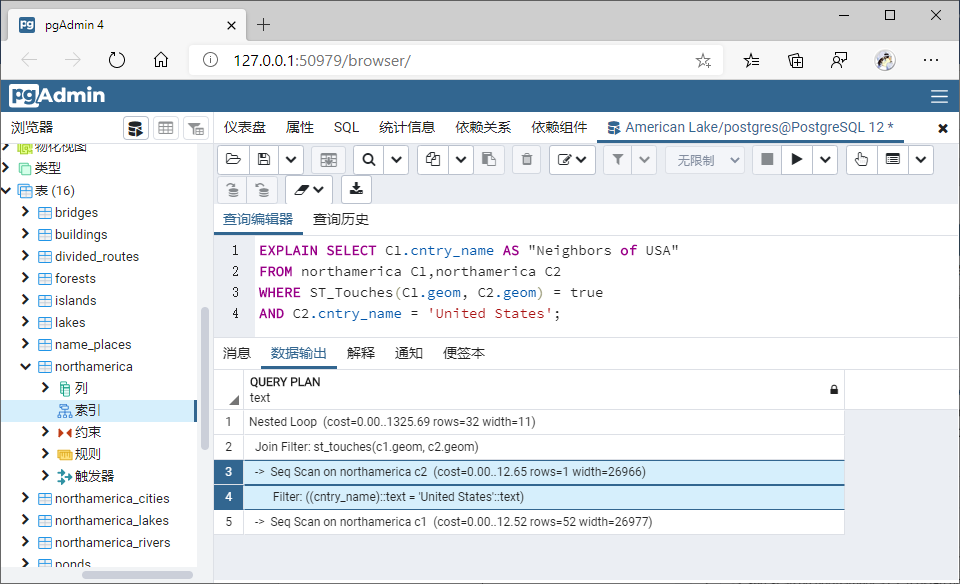
②不建立GiST索引时:
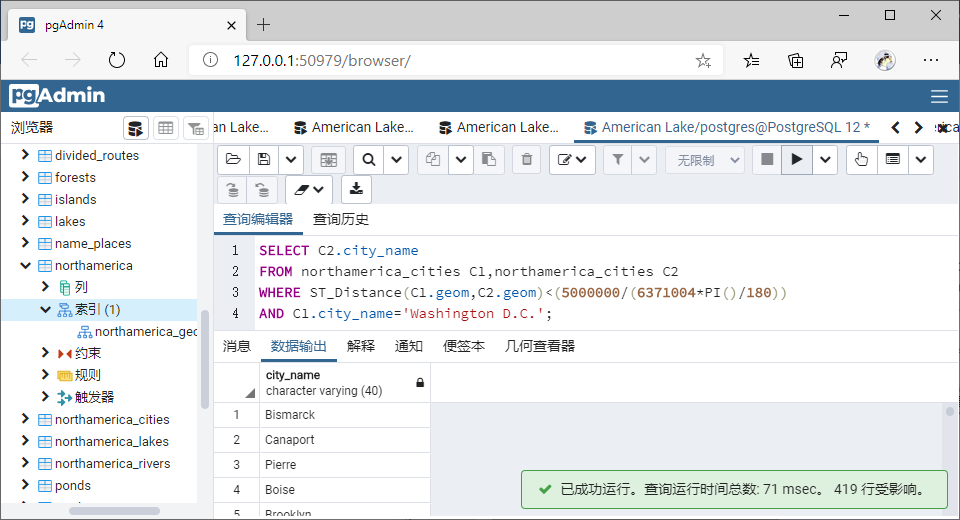
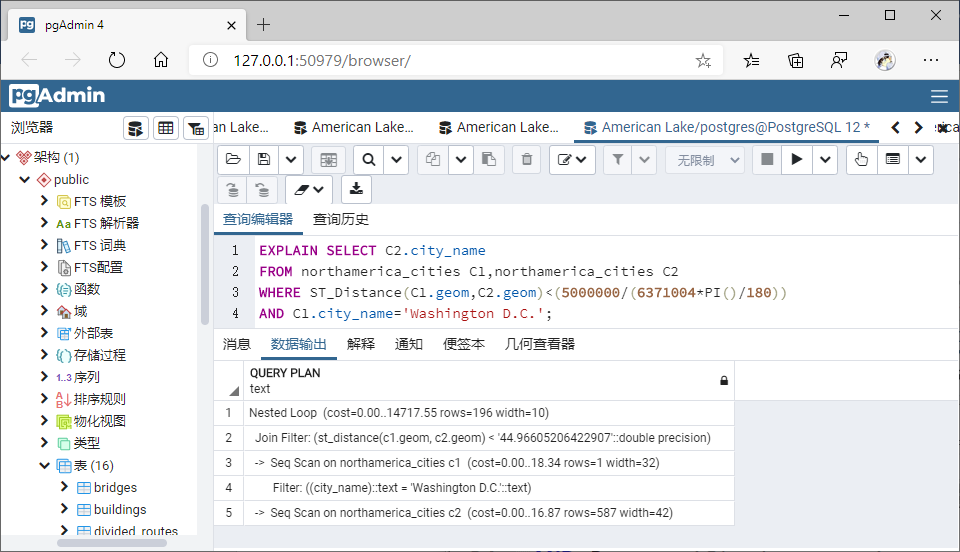
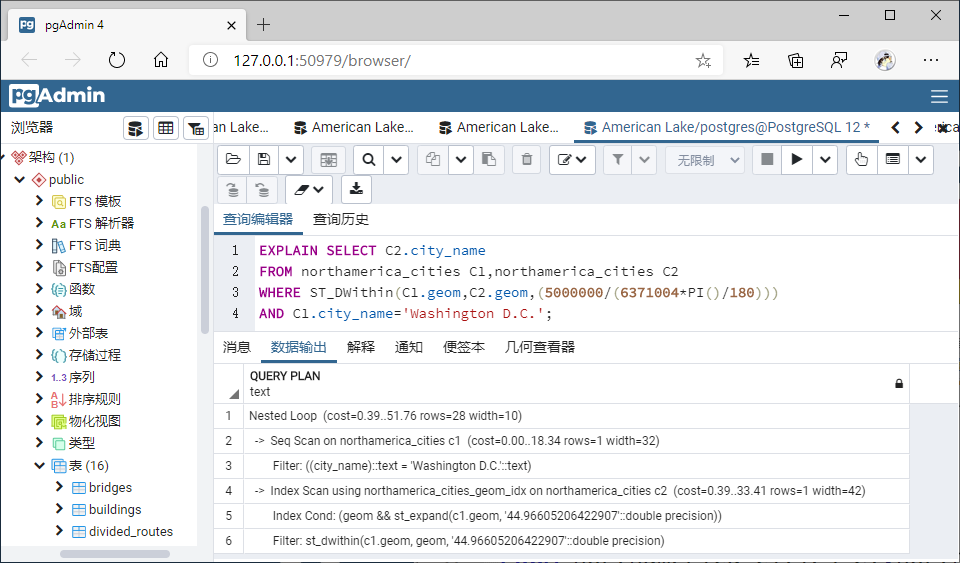
3、将不适用空间索引的函数转换为能够使用空间索引的函数进行查询,并用explain命令查看索引使用前后效率;
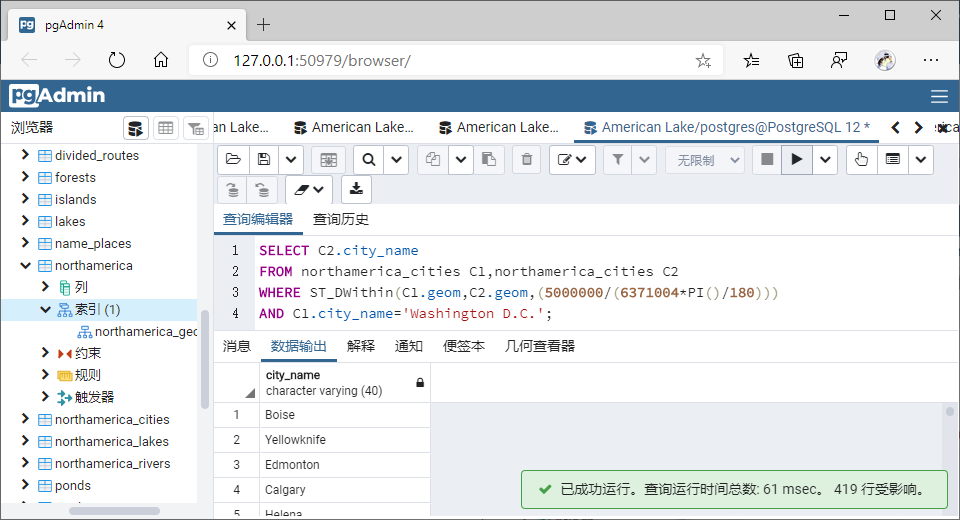
列出距离华盛顿特区5000km以内的城市:
转换前:
转换后:
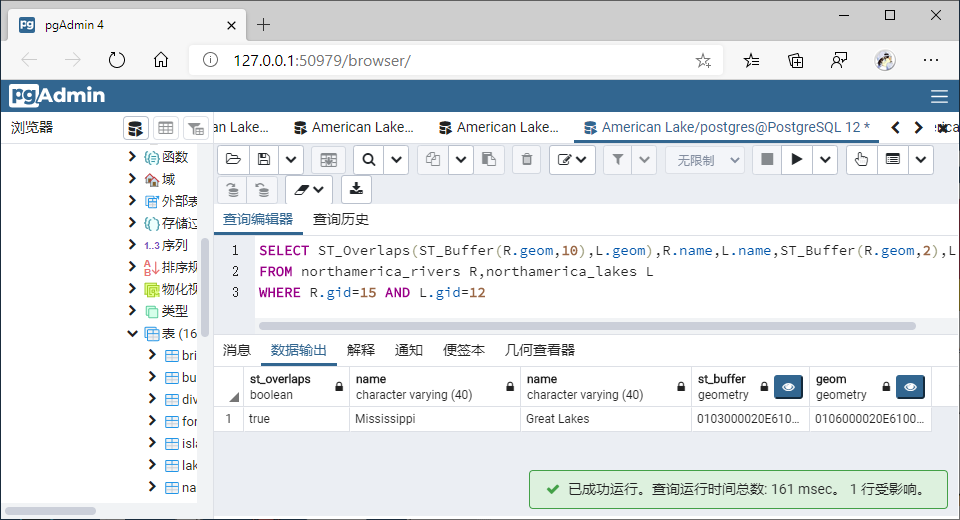
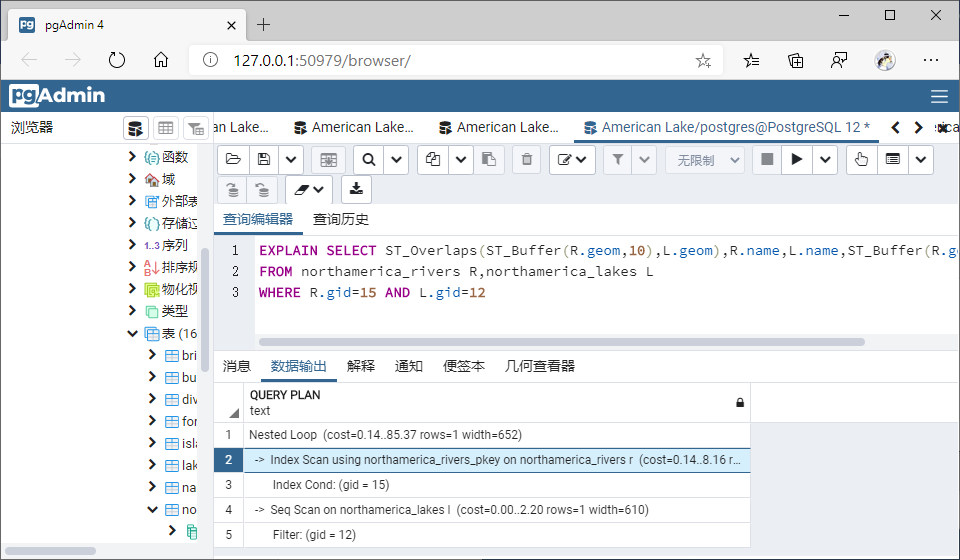
4、对比交叠、包含等空间查询函数在GiST索引和SP-GiST索引上的查询效率。
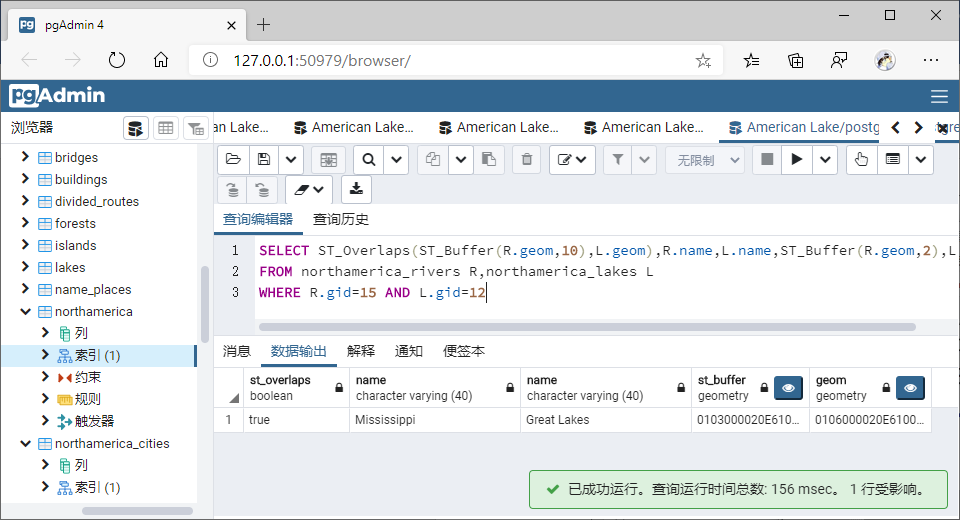
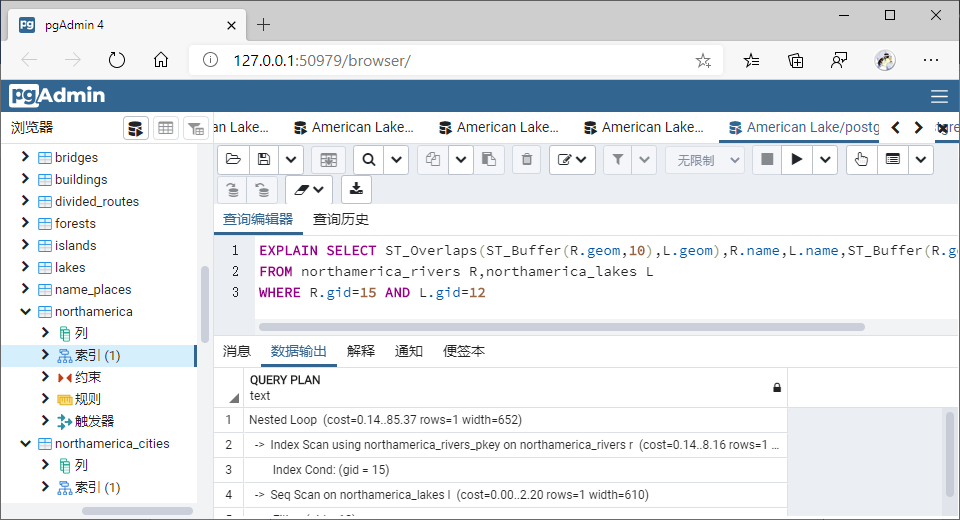
(1)交叠(Overlaps)
①GiST索引
②SP-GiST索引
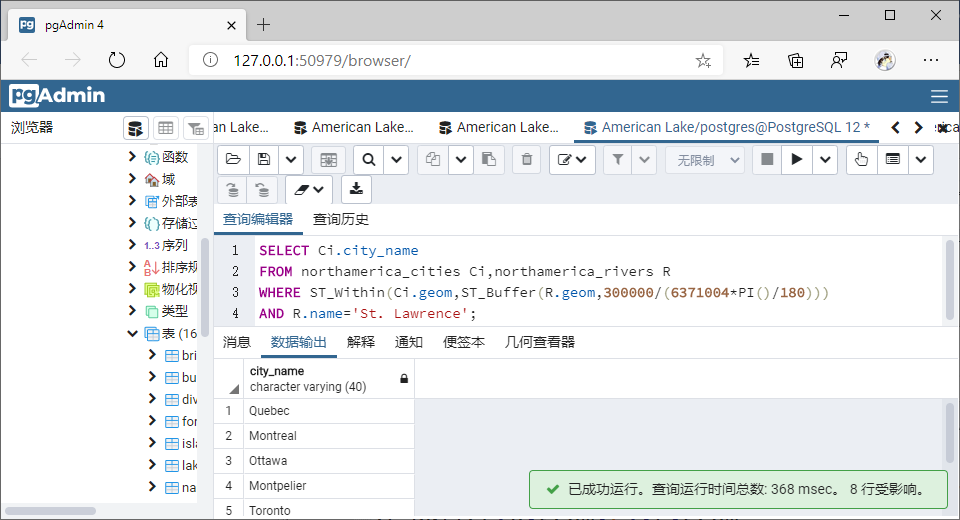
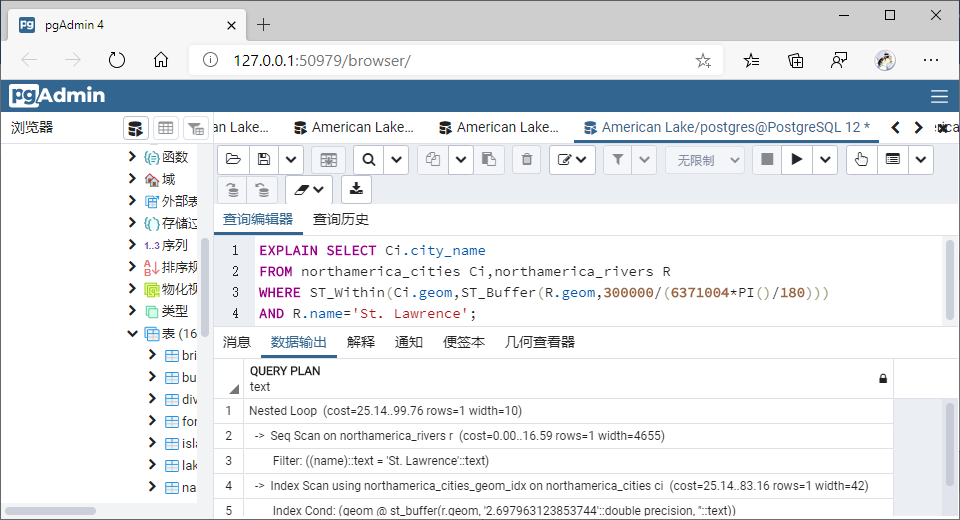
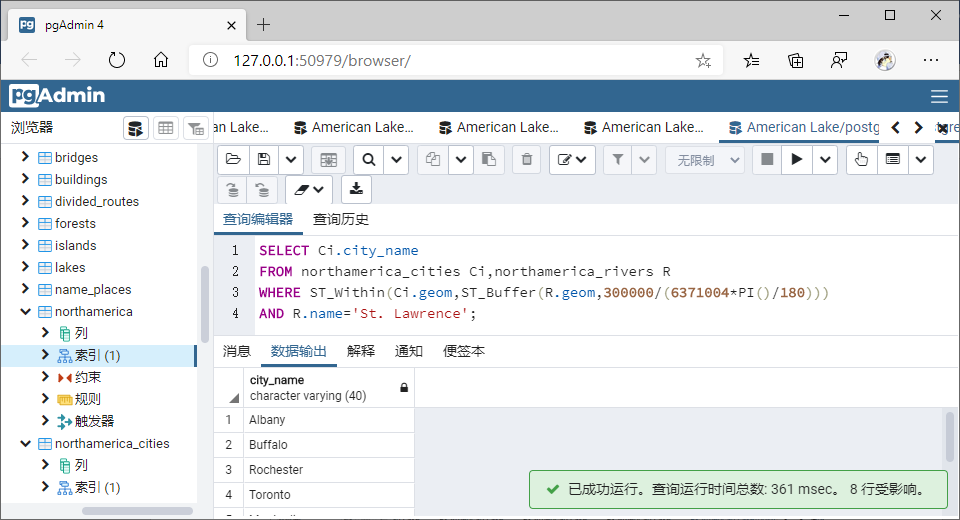
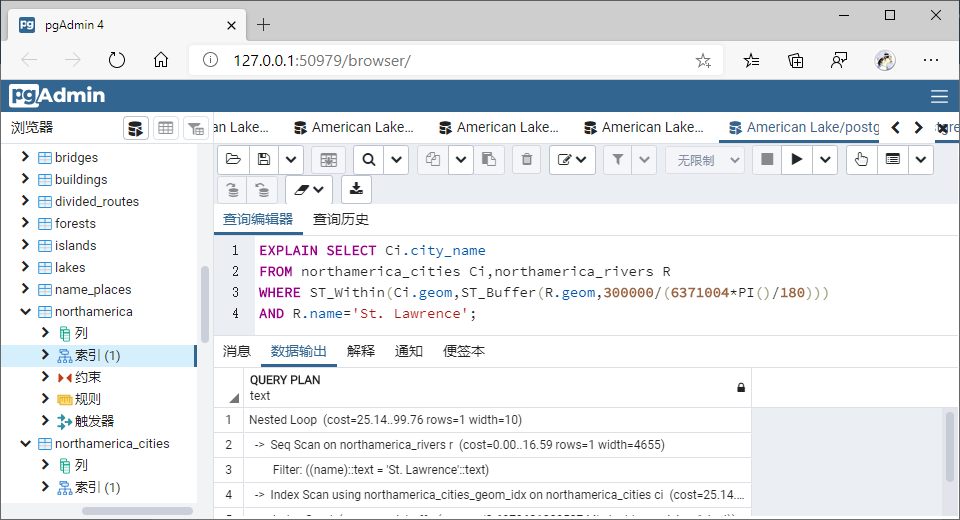
(2)包含于(Within)
①GiST索引
②SP-GiST索引
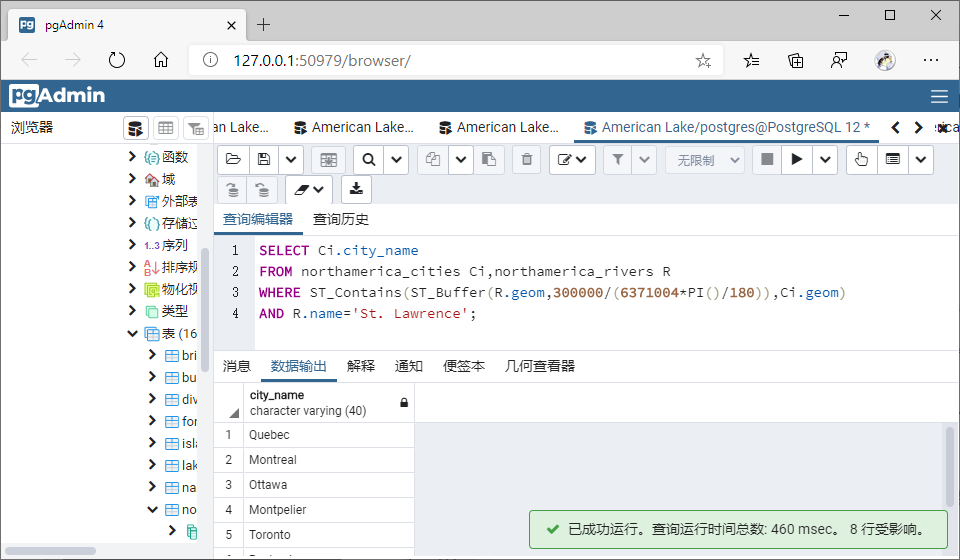
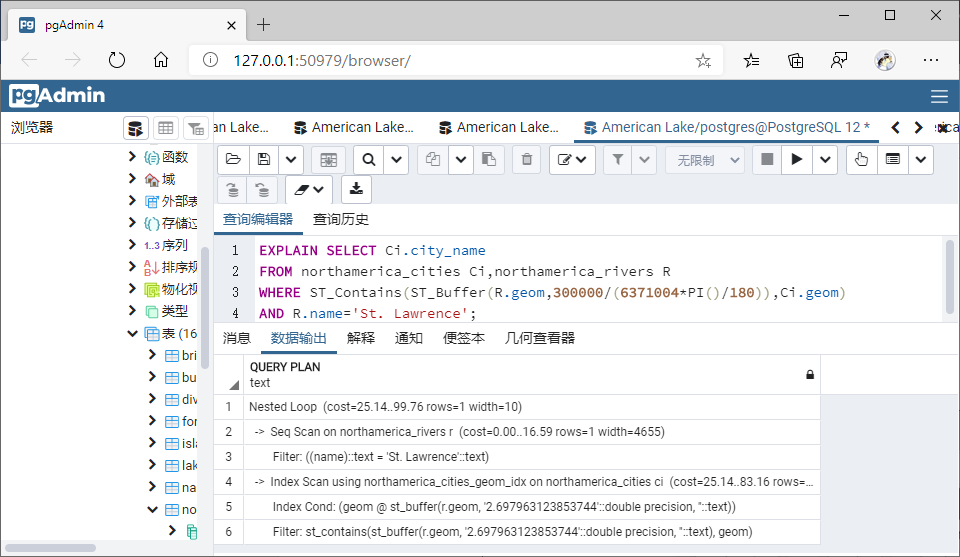
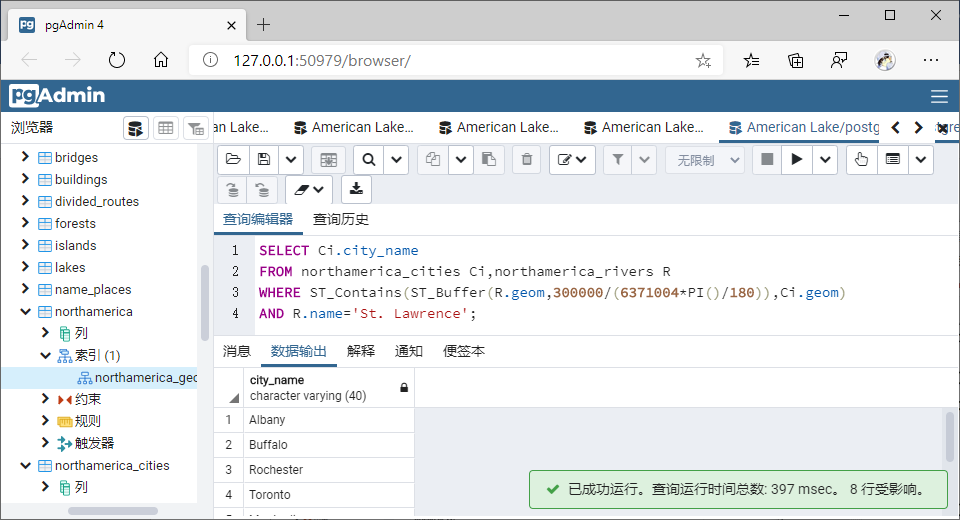
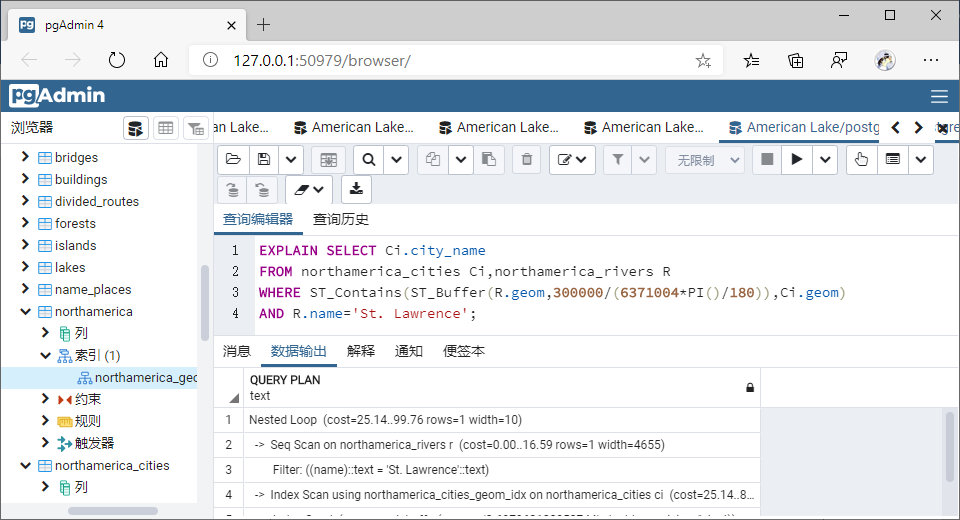
(3)包含(Contains)
①GiST索引
②SP-GiST索引
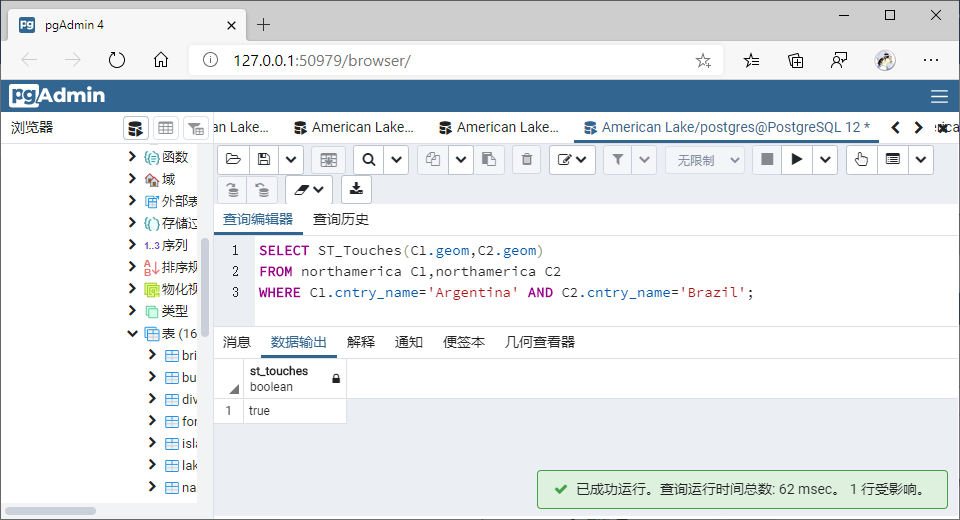
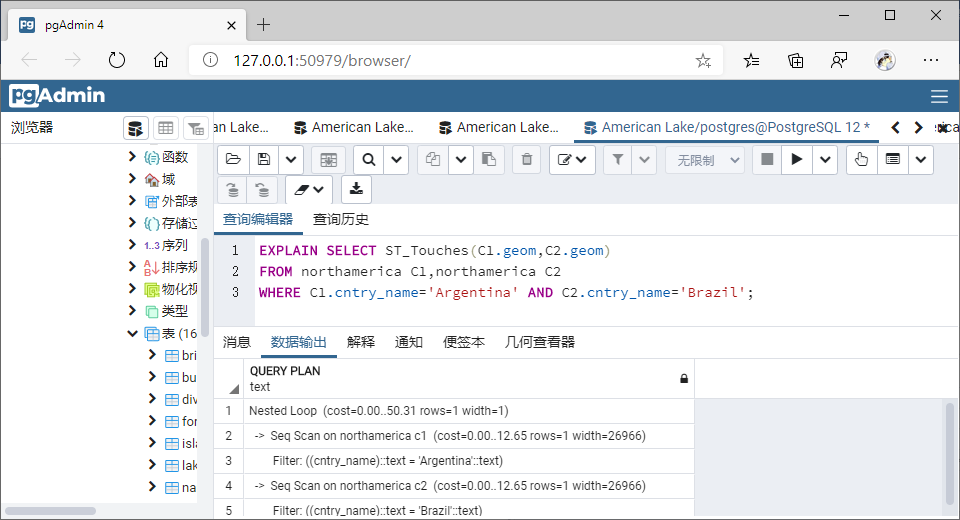
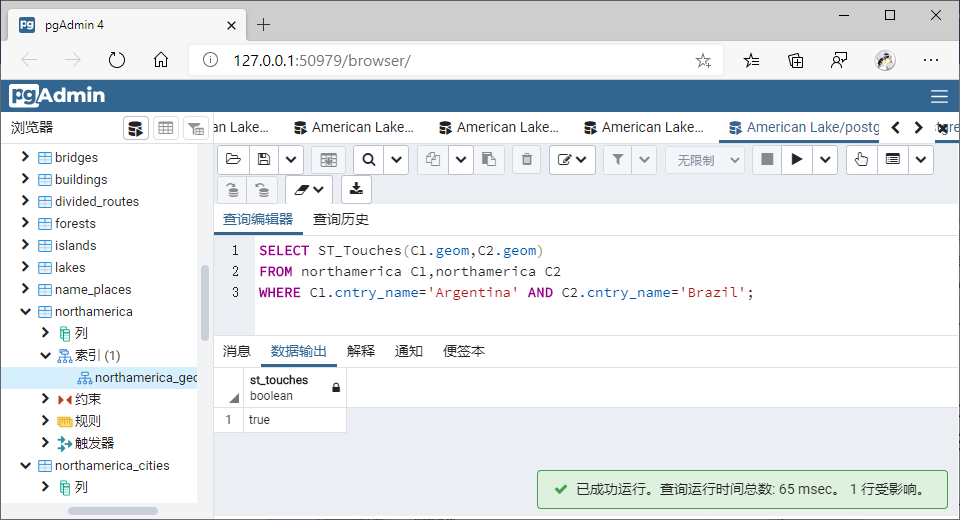
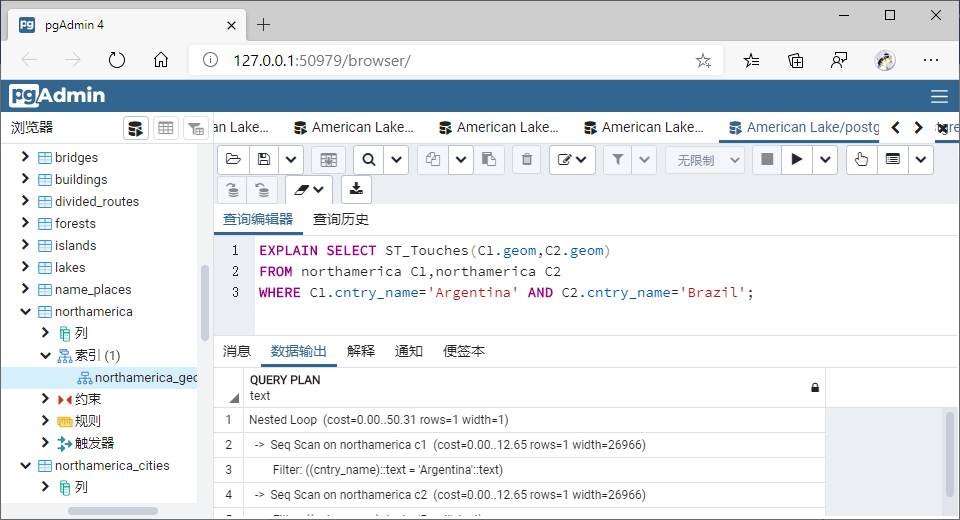
(4)相接(Touches)
①GiST索引
②SP-GiST索引
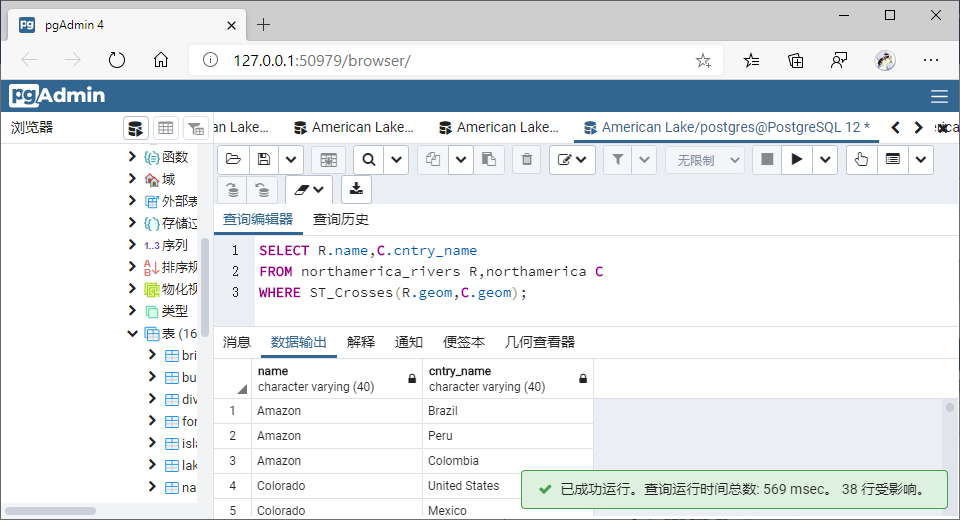
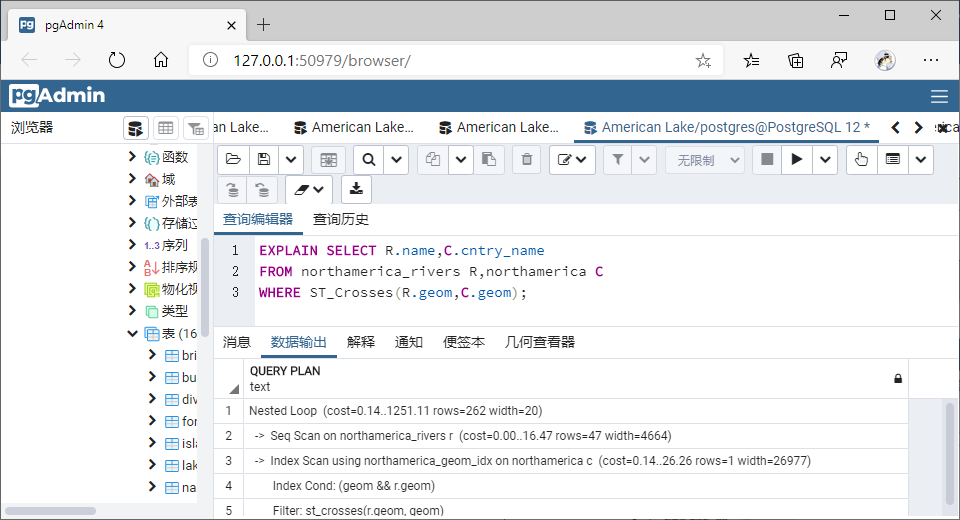
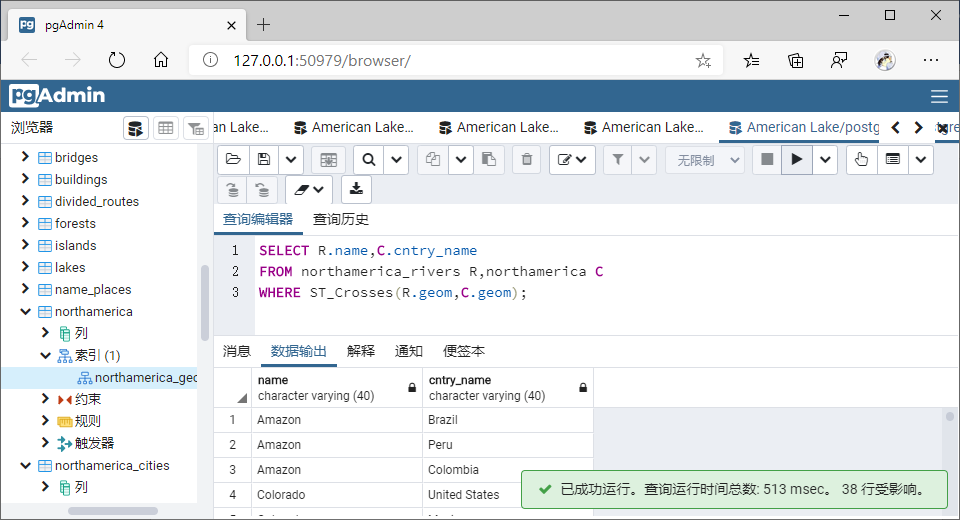
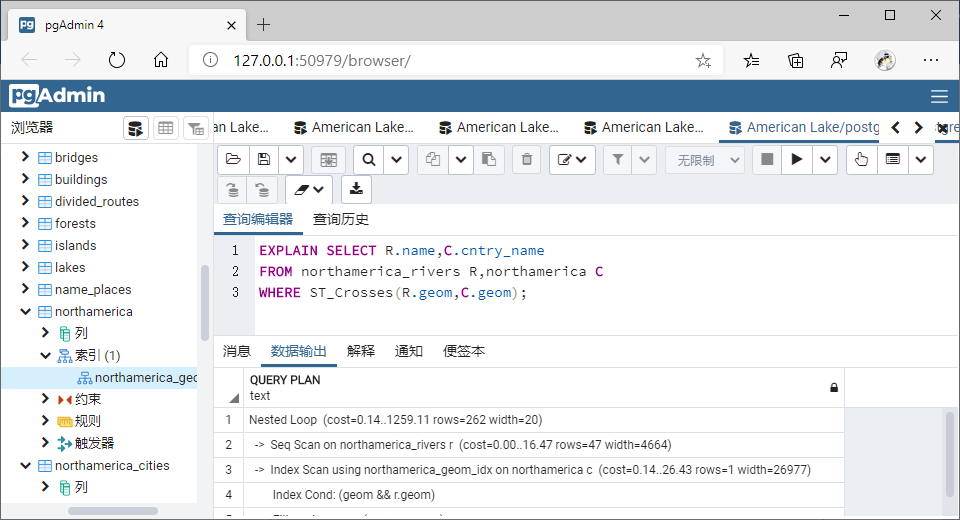
(5)穿越(Crosses)
①GiST索引
②SP-GiST索引
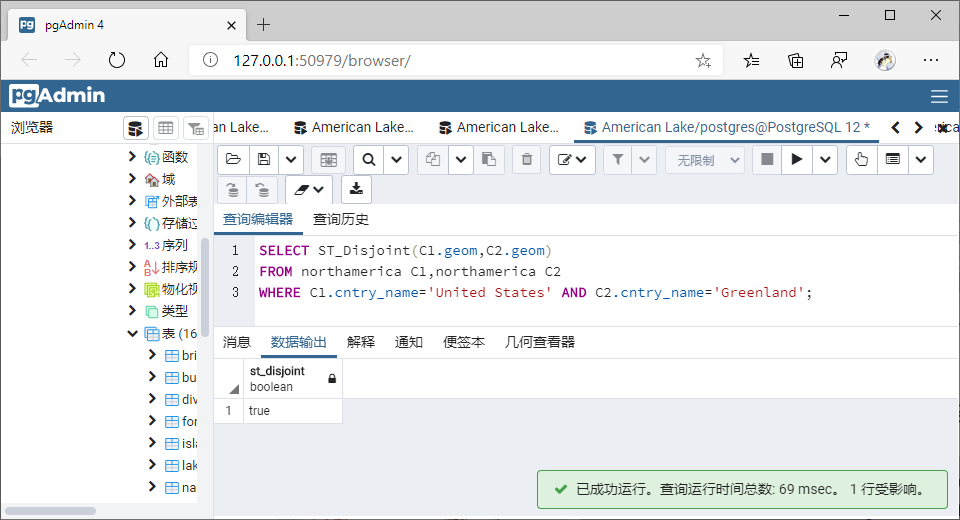
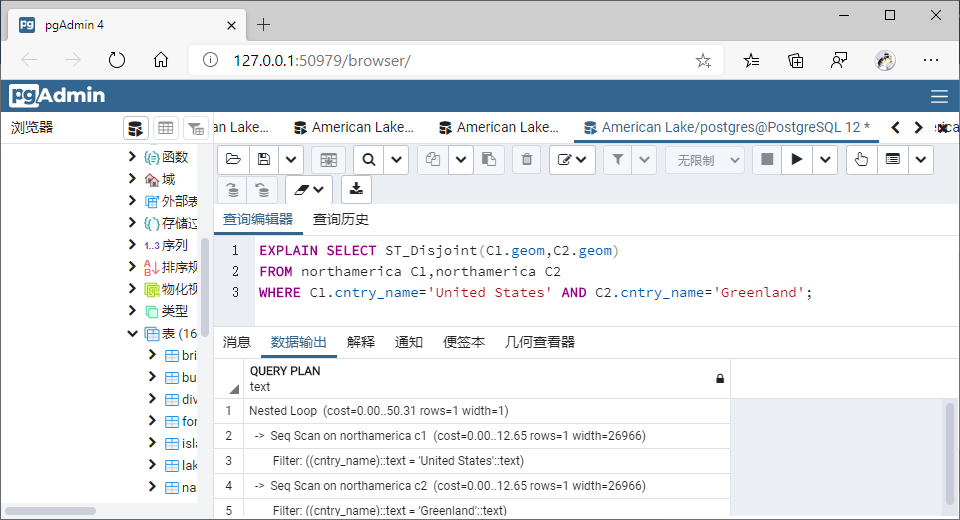
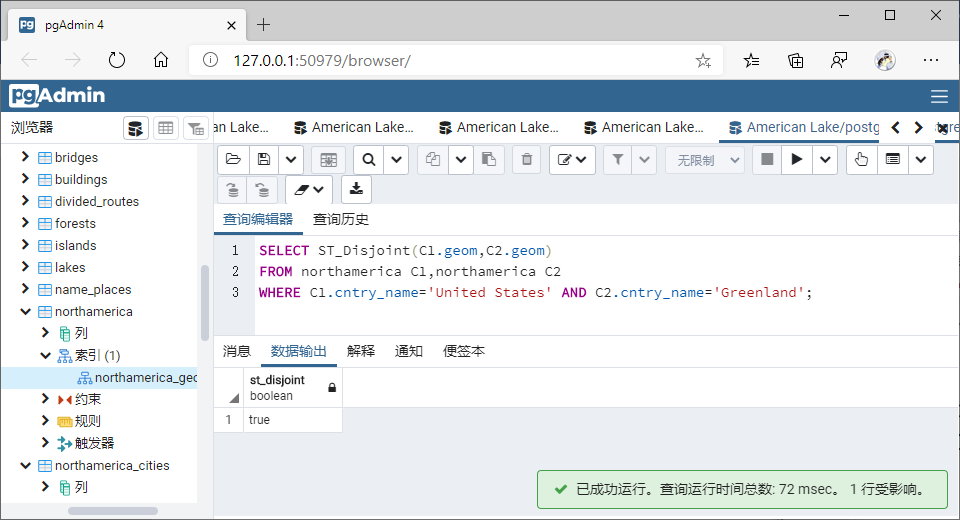
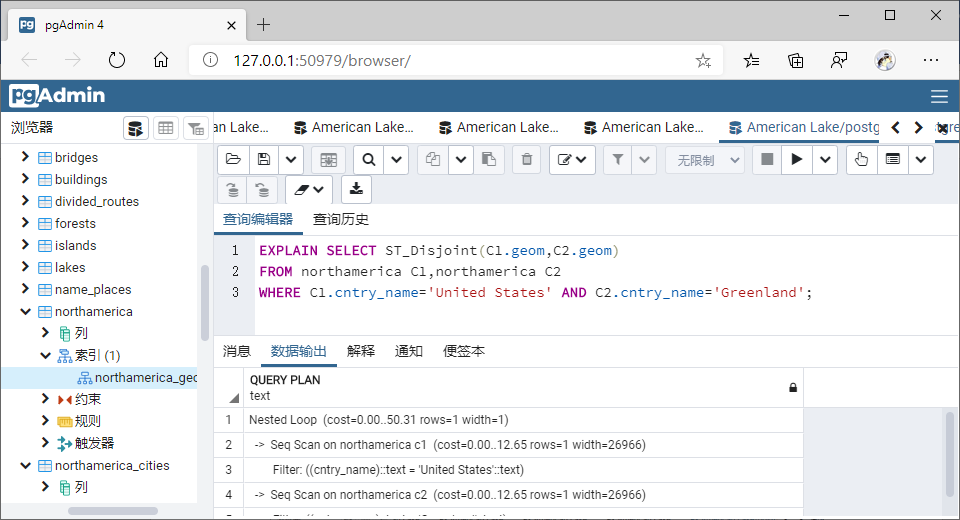
(6)相离(Disjoint)
①GiST索引
②SP-GiST索引
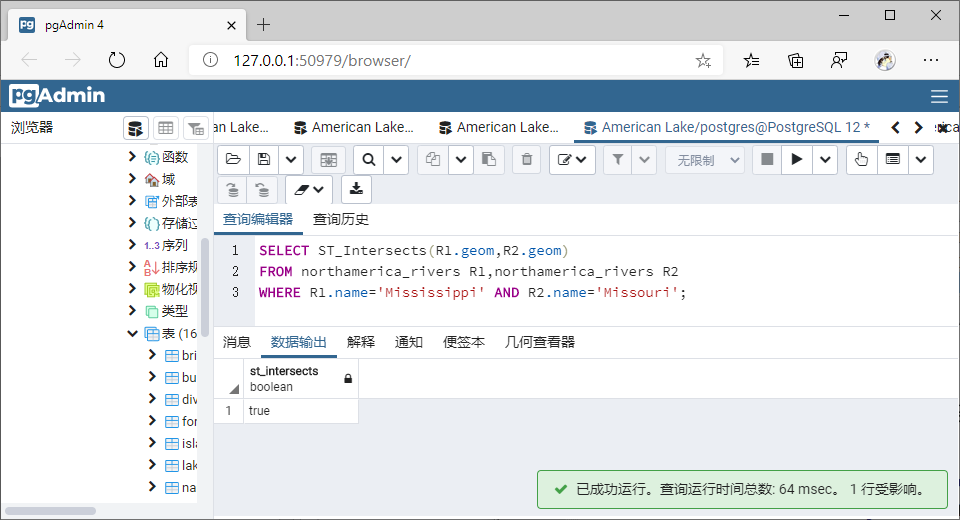
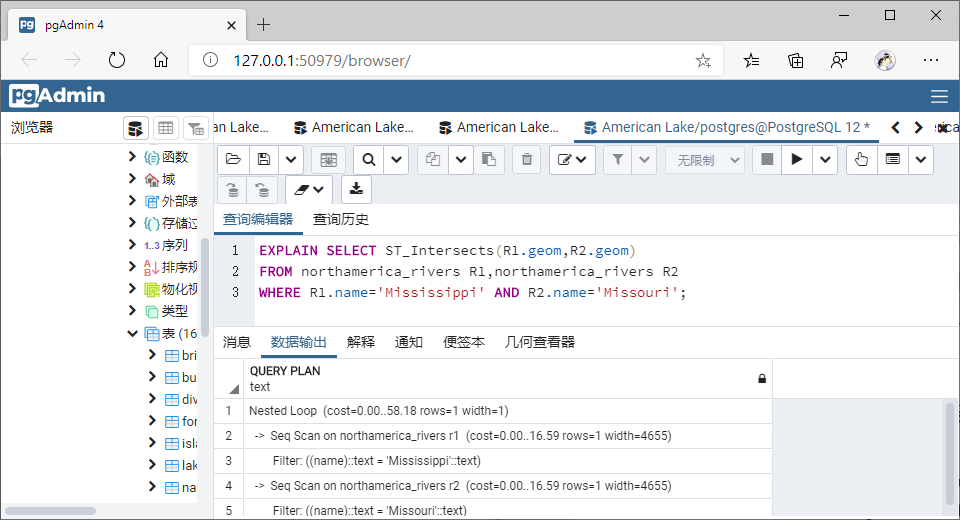
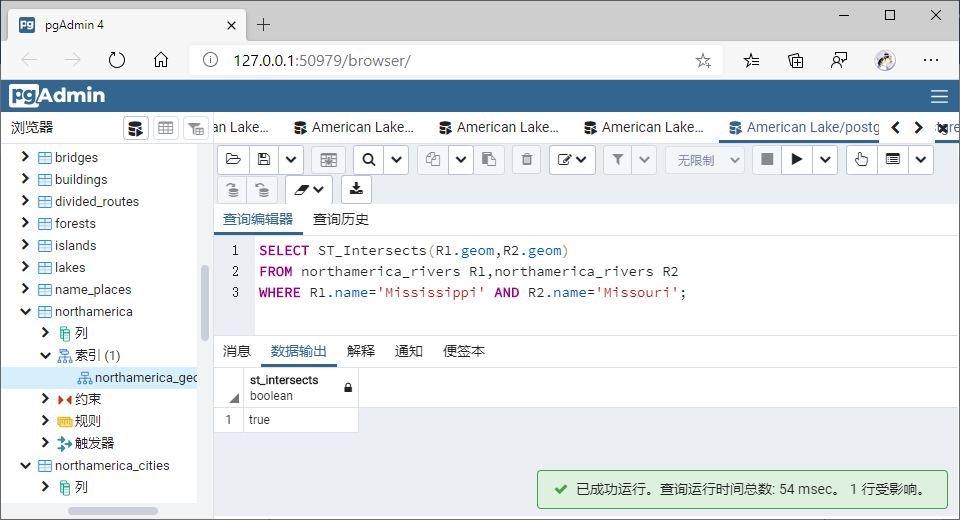
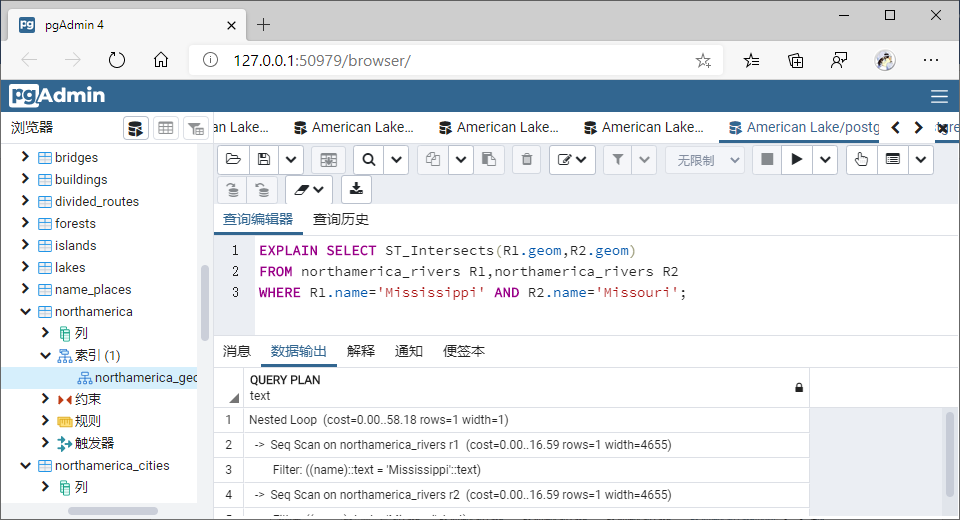
(7)相交(Intersects)
①GiST索引
②SP-GiST索引
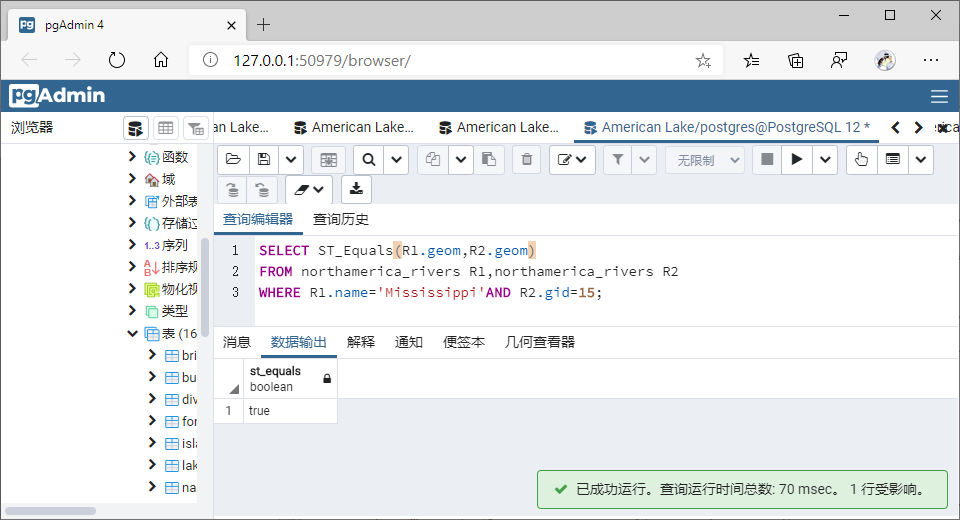
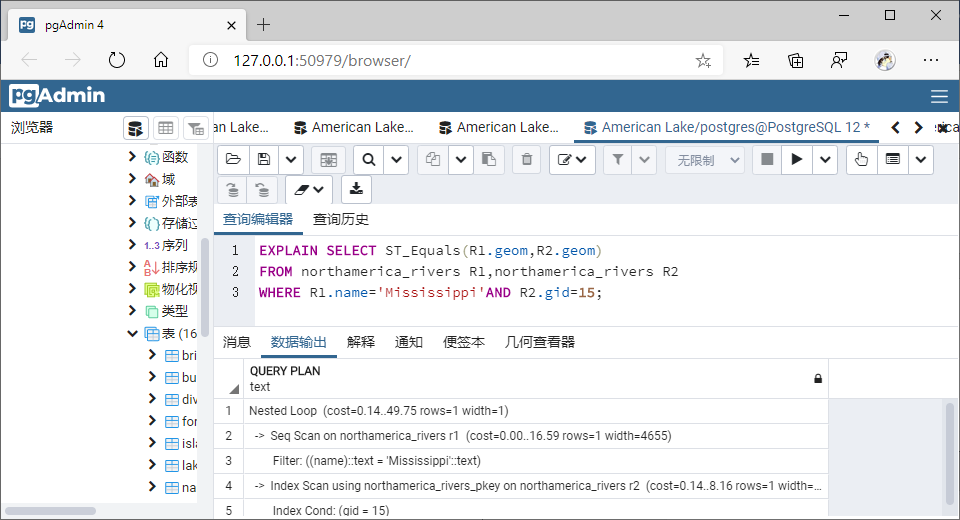
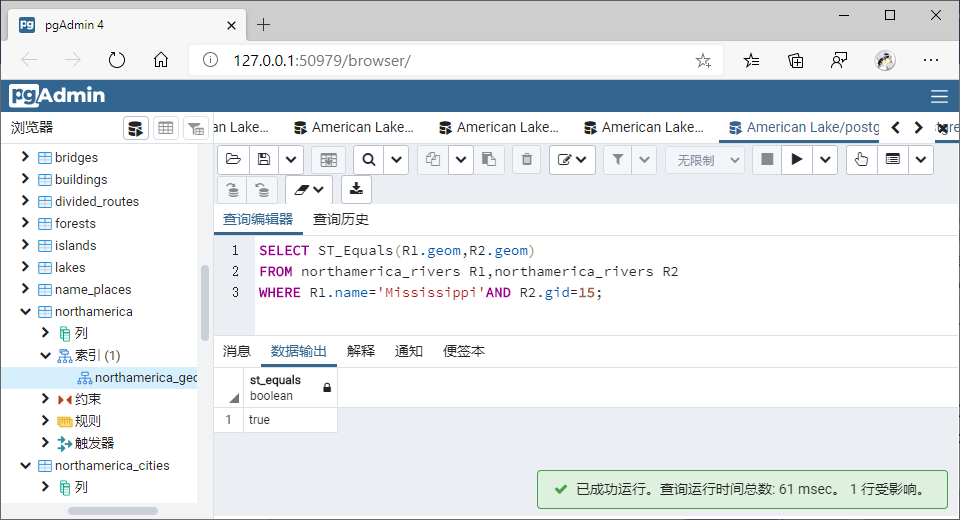
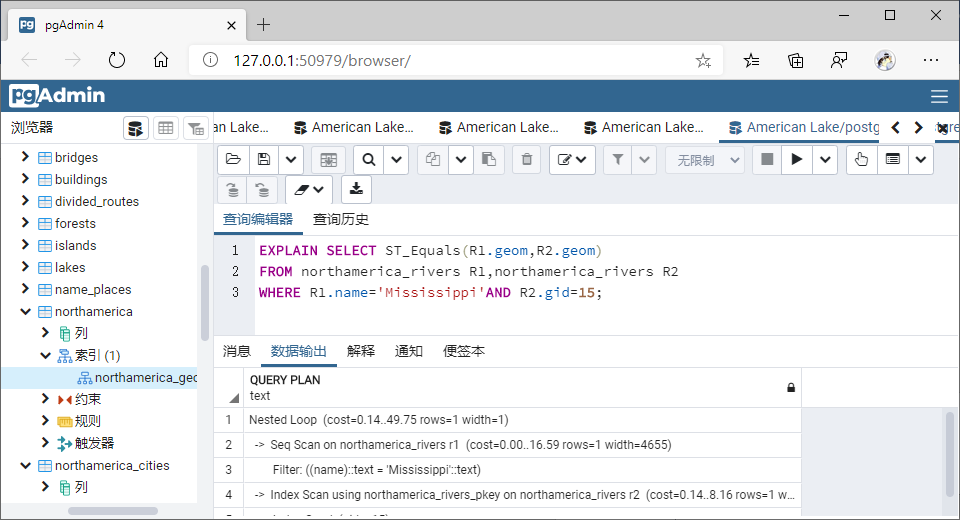
(8)相等(Equals)
①GiST索引
②SP-GiST索引
SQL代码
CREATE INDEX northamerica_geom_idx
ON northamerica USING GIST(geom);
VACUUM ANALYZE northamerica(geom);
CREATE INDEX northamerica_cities_geom_idx
ON northamerica_cities USING GIST(geom);
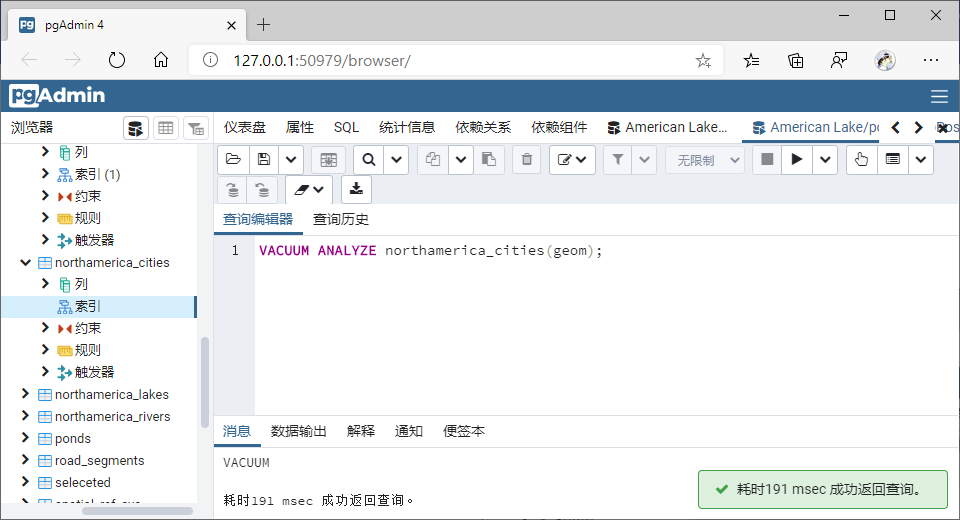
VACUUM ANALYZE northamerica_cities(geom);
CREATE INDEX northamerica_lakes_geom_idx
ON northamerica_lakes USING GIST(geom);
VACUUM ANALYZE northamerica_lakes(geom);
CREATE INDEX northamerica_rivers_geom_idx
ON northamerica_rivers USING GIST(geom);
VACUUM ANALYZE northamerica_rivers(geom);
SELECT C1.cntry_name AS "Neighbors of USA"
FROM northamerica C1,northamerica C2
WHERE ST_Touches(C1.geom, C2.geom) = true
AND C2.cntry_name = 'United States';
SELECT C1.city_name,R1.name
FROM northamerica_cities C1, northamerica_rivers R1
WHERE ST_distance(C1.geom,R1.geom) <
ALL (SELECT ST_distance (C2.geom, R1.geom)
FROM northamerica_cities C2
WHERE C1.city_name<>C2.city_name);
SELECT Ci.city_name
FROM northamerica_cities Ci,northamerica_rivers R
WHERE ST_DWithin(Ci.geom,R.geom,300000/(6371004*PI()/180))
AND R.name='St. Lawrence';
SELECT Ci.city_name
FROM northamerica_cities Ci,northamerica_rivers R
WHERE ST_Contains(ST_Buffer(R.geom,300000/(6371004*PI()/180)),Ci.geom)
AND R.name='St. Lawrence';
SELECT C2.city_name
FROM northamerica_cities C1,northamerica_cities C2
WHERE ST_Distance(C1.geom,C2.geom)<(5000000/(6371004*PI()/180))
AND C1.city_name='Washington D.C.';
SELECT C2.city_name
FROM northamerica_cities C1,northamerica_cities C2
WHERE ST_DWithin(C1.geom,C2.geom,(5000000/(6371004*PI()/180)))
AND C1.city_name='Washington D.C.';
--交叠
SELECT ST_Overlaps(ST_Buffer(R.geom,10),L.geom),R.name,L.name,ST_Buffer(R.geom,2),L.geom
FROM northamerica_rivers R,northamerica_lakes L
WHERE R.gid=15 AND L.gid=12
--含于
SELECT Ci.city_name
FROM northamerica_cities Ci,northamerica_rivers R
WHERE ST_Within(Ci.geom,ST_Buffer(R.geom,300000/(6371004*PI()/180)))
AND R.name='St. Lawrence';
--包含
SELECT Ci.city_name
FROM northamerica_cities Ci,northamerica_rivers R
WHERE ST_Contains(ST_Buffer(R.geom,300000/(6371004*PI()/180)),Ci.geom)
AND R.name='St. Lawrence';
--相接
SELECT ST_Touches(C1.geom,C2.geom)
FROM northamerica C1,northamerica C2
WHERE C1.cntry_name='Argentina' AND C2.cntry_name='Brazil';
--穿越
SELECT R.name,C.cntry_name
FROM northamerica_rivers R,northamerica C
WHERE ST_Crosses(R.geom,C.geom);
--相离
SELECT ST_Disjoint(C1.geom,C2.geom)
FROM northamerica C1,northamerica C2
WHERE C1.cntry_name='United States' AND C2.cntry_name='Greenland';
--相交
SELECT ST_Intersects(R1.geom,R2.geom)
FROM northamerica_rivers R1,northamerica_rivers R2
WHERE R1.name='Mississippi' AND R2.name='Missouri';
--相等
SELECT ST_Equals(R1.geom,R2.geom)
FROM northamerica_rivers R1,northamerica_rivers R2
WHERE R1.name='Mississippi'AND R2.gid=15;
CREATE INDEX northamerica_geom_idx
ON northamerica USING SPGIST(geom);
CREATE INDEX northamerica_cities_geom_idx
ON northamerica_cities USING SPGIST(geom);
CREATE INDEX northamerica_lakes_geom_idx
ON northamerica_lakes USING SPGIST(geom);
CREATE INDEX northamerica_rivers_geom_idx
ON northamerica_rivers USING SPGIST(geom);
VACUUM ANALYZE northamerica(geom);
VACUUM ANALYZE northamerica_cities(geom);
VACUUM ANALYZE northamerica_lakes(geom);
VACUUM ANALYZE northamerica_rivers(geom);